Day 32
MATH 313: Survey Design and Sampling
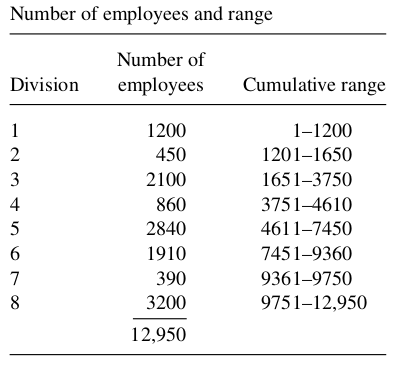
Example 1 (Example 8.12 Textbook) An auditor wishes to sample sick-leave records of a large firm in order to estimate the average number of days of sick leave per employee over the past quarter. The firm has eight divisions, with varying numbers of employees per division. Because number of days of sick leave used within each division should be highly correlated with the number of employees, the auditor decides to sample \(n=3\) divisions with probabilities proportional to number of employees. Show how to select the sample if the numbers of employees in the eight divisions are \(1200,450,2100,860,2840,1910,390, and 3200\). Suppose the total number of sick-leave days used by the three sampled divisions during the past quarter are, respectively, \[ \tau_1=4320 \quad \tau_2=4160 \quad \tau_3=5790 \]