Day 28
MATH 313: Survey Design and Sampling
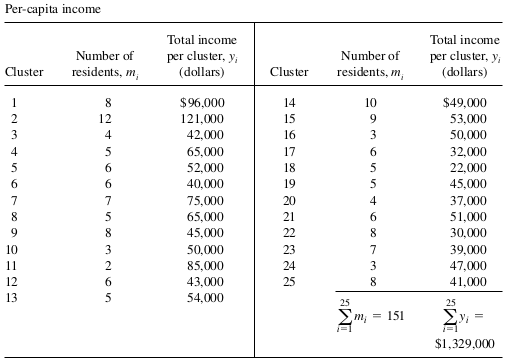
Example 1: A sociologist wants to estimate the per-capita income in a certain small city. No list of resi- dent adults is available. So she performed cluster sampling. The city is marked off into rectangular blocks, except for two industrial areas and three parks that contain only a few houses. The sociologist decides that each of the city blocks will be considered one cluster, the two industrial areas will be considered one cluster, and finally, the three parks will be considered one cluster. The clusters are numbered on a city map, with the numbers from 1 to 415.The experimenter has enough time and money to sample clusters and to interview every household within each cluster. Hence, 25 random numbers between1 and 415 are selected, and the clusters having these numbers are marked on the map.Interviewers are then assigned to each of the sampled clusters. The data on incomes are presented in the following. Use the data to estimate the per-capita income in the city and place a bound on the error of estimation.