Day 27
MATH 313: Survey Design and Sampling
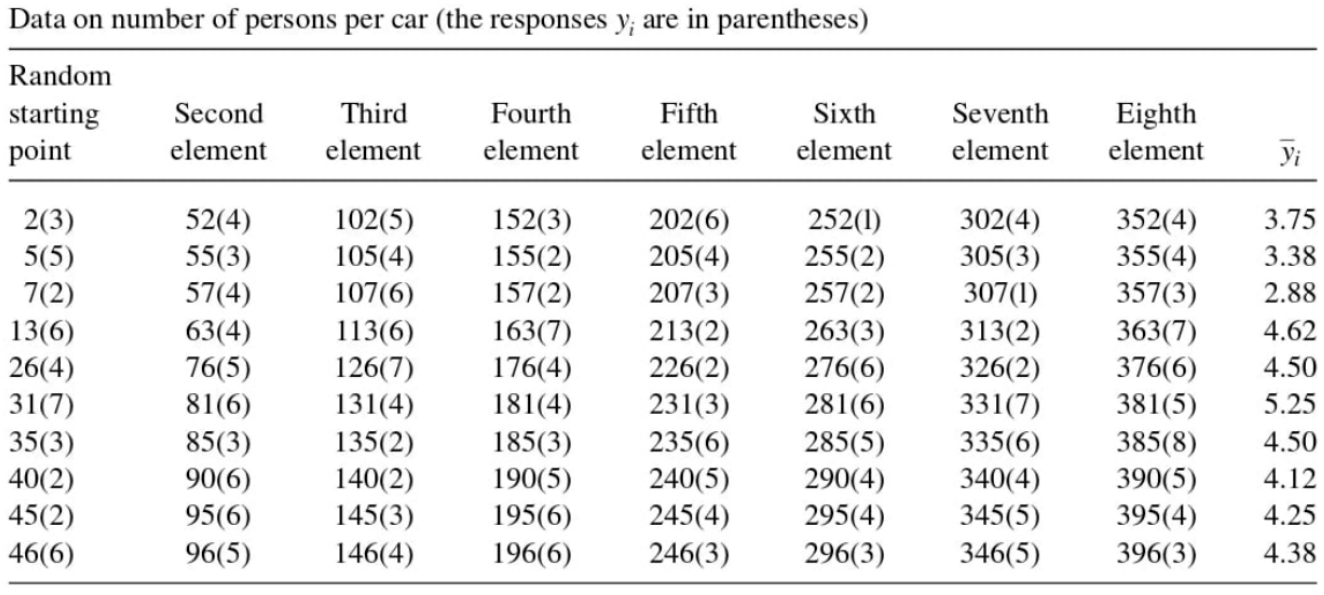
Example 1: A state park charges admission by carload rather than by person, and a park official wants to estimate the average number of people per car for a particular summer holiday. She knows from past experience that there should be approximately 400 cars entering the park, and she wants to sample 80 cars. To obtain an estimate of the variance, she uses repeated systematic sampling with ten samples of eight cars each. Using the data given in the following table, estimate the average number of people per car and place a 95% bound on the error of estimation.